Attention
We have updated the RBPsuite web server, the old version can be found here: RBPsuite1.0
* The software is free to academic users ONLY; For commercial usage, please contact with us.
* Please do not use any crawler tools or submit frequently in a very short time (especially the general model).
* Due to the limitation of computing resources, we temporarily support prediction for files below 500Kb.
* If you want to predict RBP binding nucleotides on RNAs, base-resolution model iDeepB can be used.
* RBPsuite was frequently used (search results at Google Scholar) by wet-lab scientist, many of them may not cite our paper.
Input
RBPsuite requires three types of input: RNA type, Prediction model, and RNA sequence. Email address is optional. If an email is provided, a notification will be sent to the email once the job is finished.
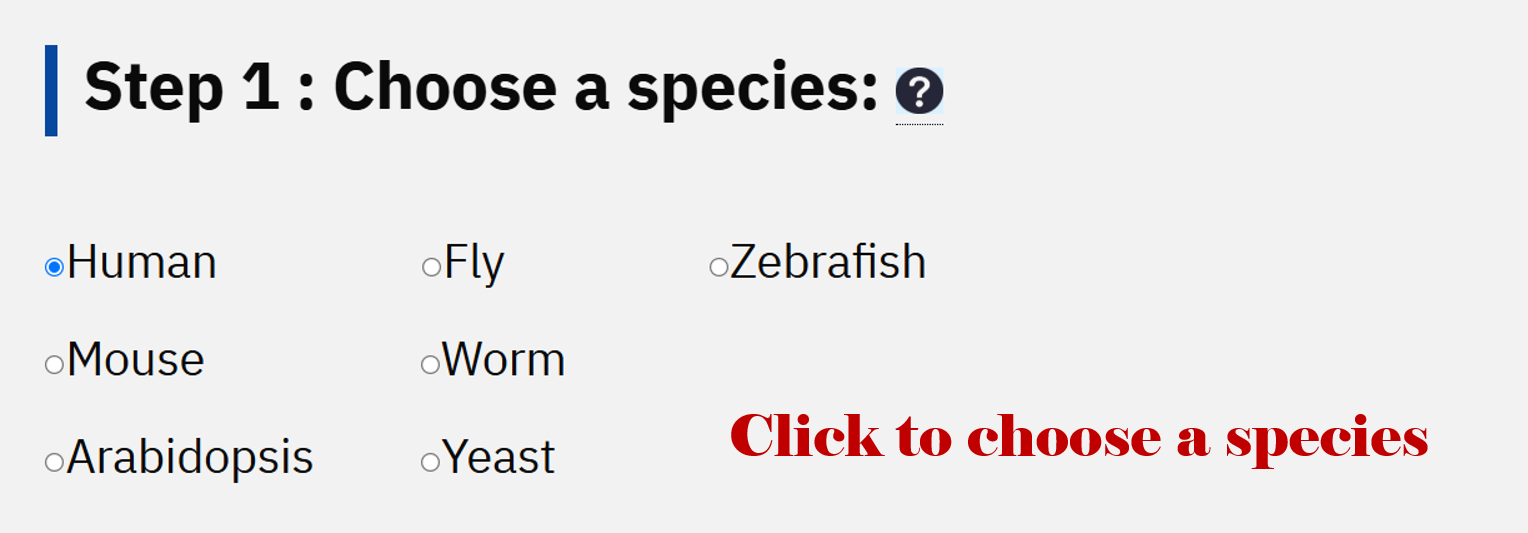
1. Species
More species (Human, Mouse, Arabidopsis, Fly, Worm, Yeast, and Zebrafish) are available now for the RBPsuite linear RNA prediction model!
There are 223 RBPs for human linear RNAs, 46 RBPs for mouse linear RNAs, 5 RBPs for arabidopsis linear RNAs, 7 RBPs for fly linear RNAs, 6 RBPs for worm linear RNAs, 65 RBPs for yeast linear RNAs, 1 RBP for zebrafish linear RNAs.
2. RNA type
You need to choose the type of your RNA, whether it belongs to linear RNA or circRNA, and they will be predicted by different models. If you are not sure which RNA type your input sequence belongs to, you can first use our developed
WebCircRNA to assess the circRNA potential, then choose the RNA type.

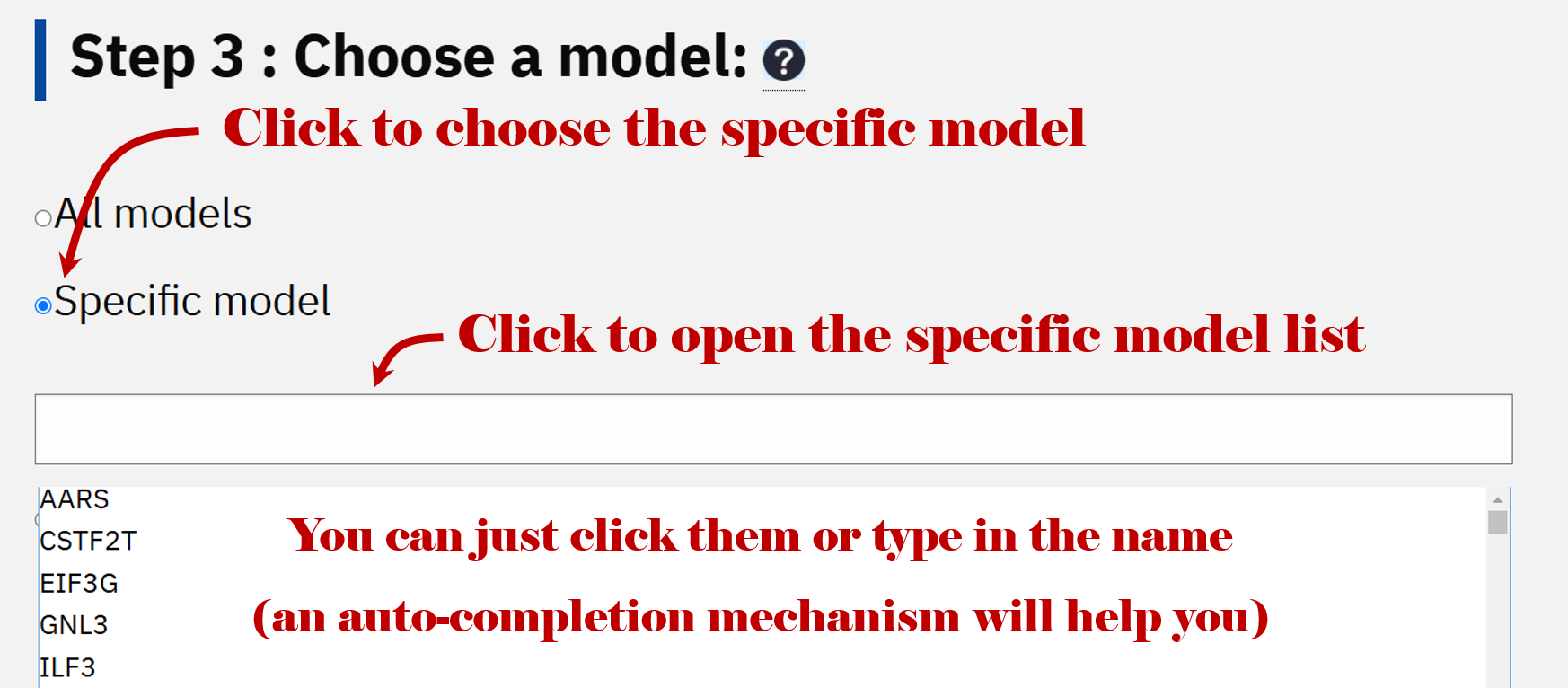
3. Predition model
RBPsuite provides two types of prediction models: General model (all available RBPs) and the Specific model (one specific RBP). If you know exactly about your protein name, please use the Specific model. Otherwise, please choose the General model, which will predict interaction scores between all RBPs and this input RNA.
3.1 Specific model
There are 223 (human) specific models for linear RNA and 37 for circRNA in RBPsuite. Each model is trained by the known RNA targets of the RBP. Here we only predict the binding scores between the input RNA and the specified RBP.
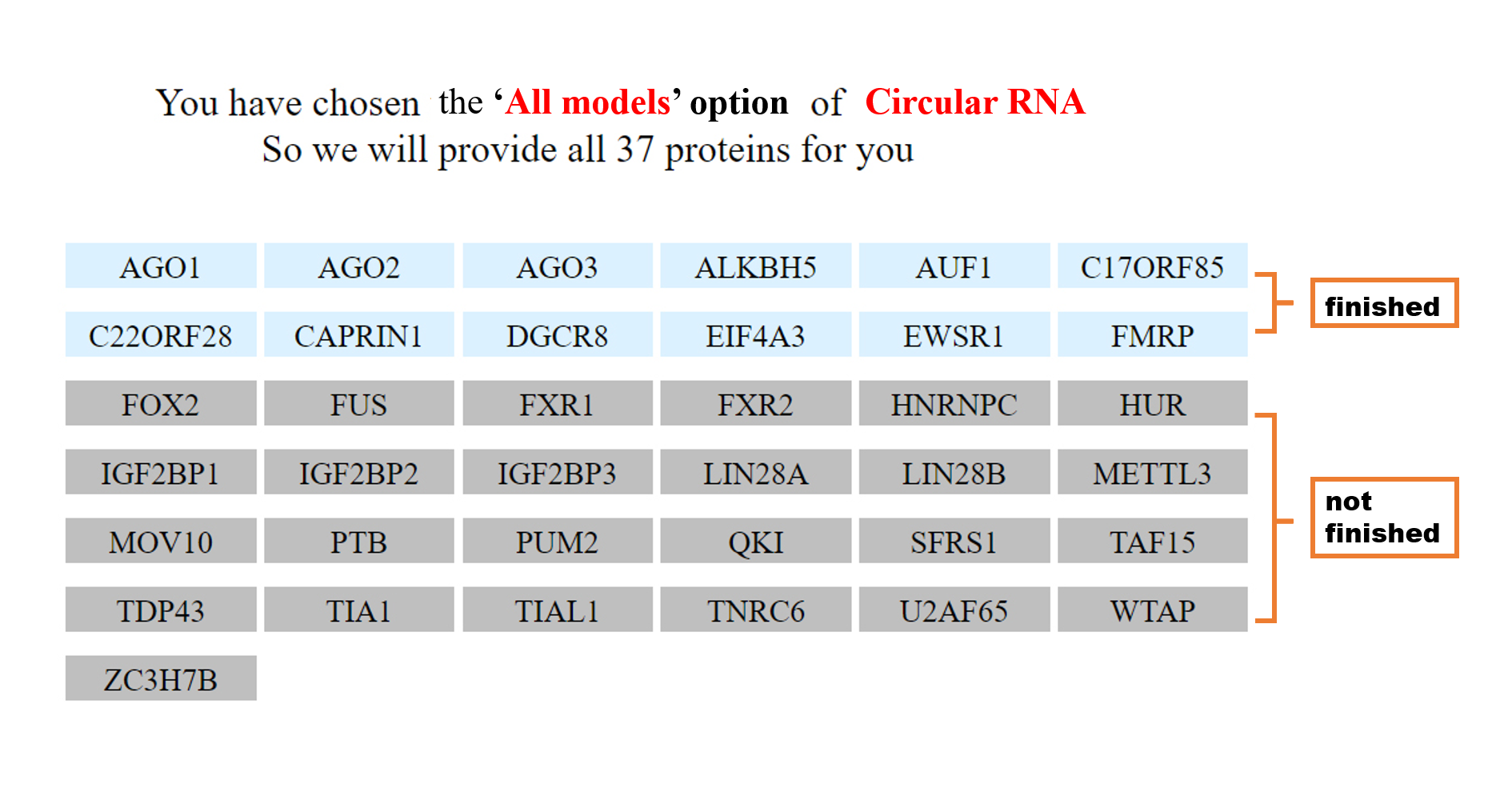
3.2 All models
The 'All models' option will use all the specific models(223 RBPs (human) for linear RNAs and 37 RBPs for circRNA) to predict binding site scores. If the input RNA is linear RNA, it predicts the binding scores between this input RNA and 223 RBPs using iDeepS. If the input RNA is circRNA, it predicts the binding scores between the input RNA and 37 RBPs using CRIP.

3.3.1 General model for unseen protein
RBPsuite provides the prediction for unseen proteins. If your protein is not in the specific model list or you are not sure about the name of your protein, you can choose the option 'General model for unseen protein' in STEP 3 and then input your protein sequence. (single sequence ONLY) The general model of RBPsuite is an RBP-general binding prediction model enhanced by both RBP and RNA sequence information. It was trained on 134 eCLIP RBP datasets from ENCODE and can provide the prediction for any unseen protein.
Currently, RBPsuite only provides this function for predicting the binding site of 'Human' proteins and 'Linear RNA'.

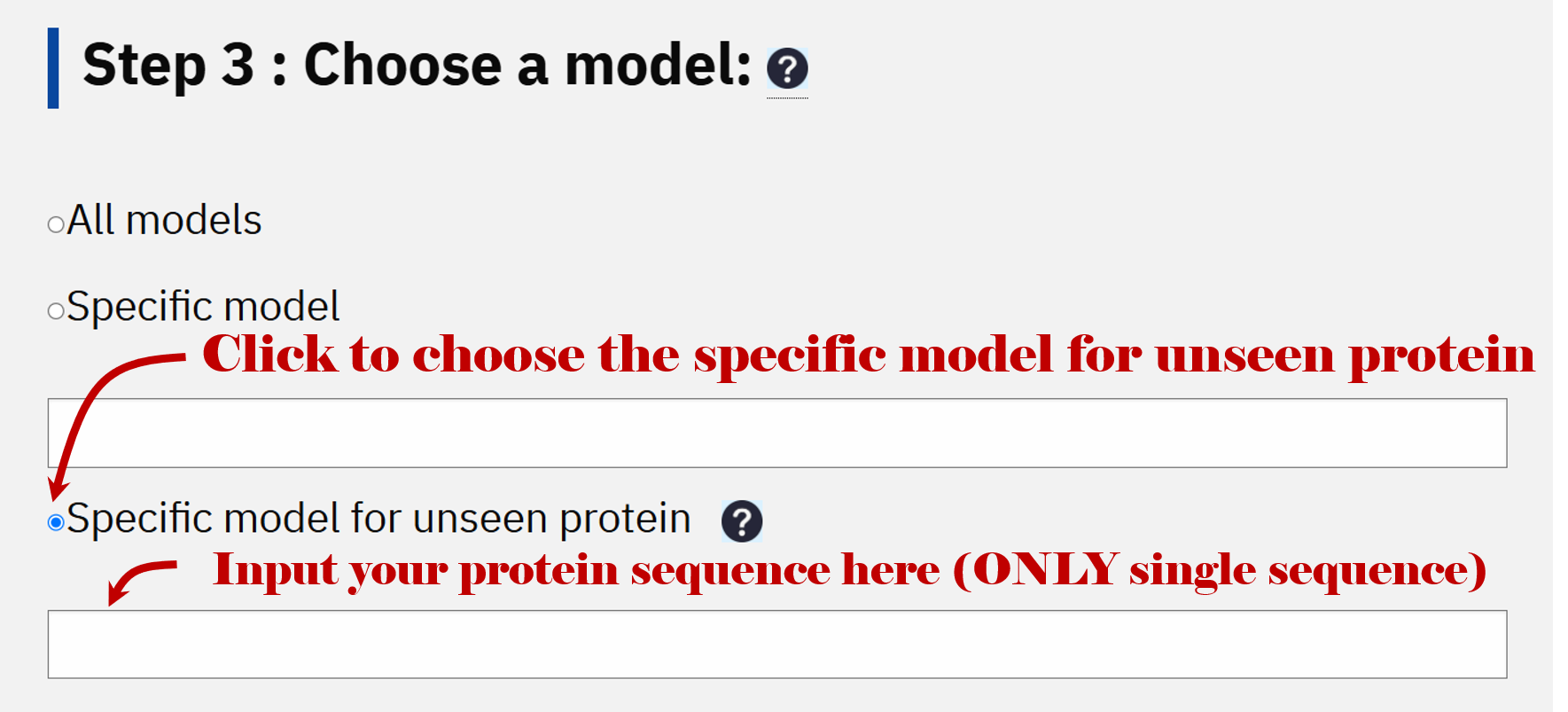
3.3.2 Specific model for unseen protein
RBPsuite also provides the prediction for unseen proteins. If your protein is not in the specific model list or you are not sure about the name of your protein, you can choose the option 'Specific model for unseen protein' in STEP 3 and then input your protein sequence. (single sequence ONLY) RBPsuite will do alignment in the database concluding all the proteins in the specific model list and find the best match of your protein, then predict with that model.
Currently, RBPsuite only provides this function for predicting the binding site of 'Yeast' proteins and 'Linear RNA'.
4. RNA sequence
You can type in your RNA sequence or upload your sequence file in FASTA format. (You can also use the example sequence.)
5. Email
Email address is optional. RBPsuite will send the results to the email address if it is provided.
Output
It will take a while for the program to run. The result page URL is given but the result hasn't been finished, so you can bookmark this URL and come back later or wait for a while.
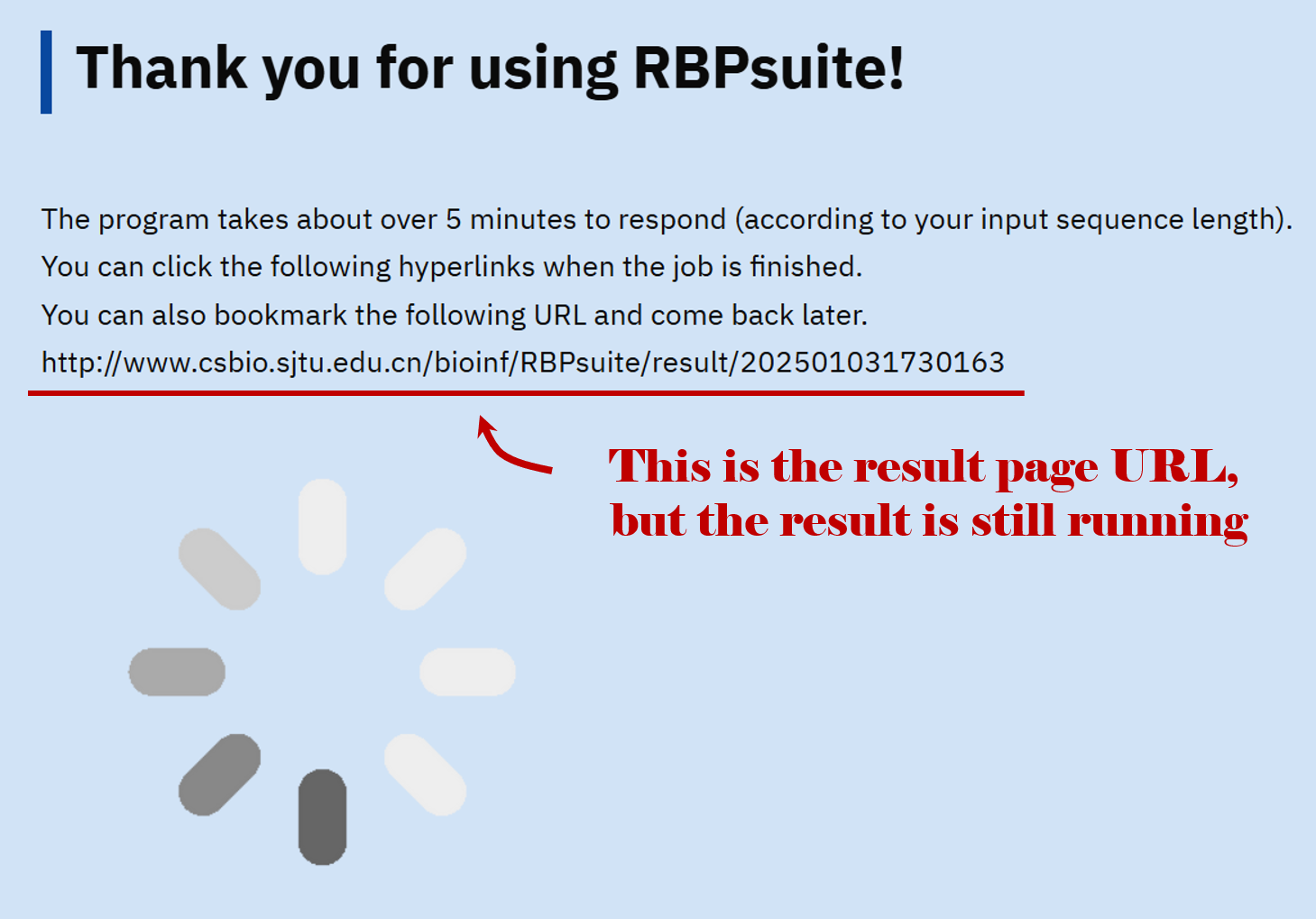
After a while, the result page is ready and you can click this URL to the result page.
1. Specific model
If the RNA-binding protein has a verified motif, RBPsuite will provide the motif logo, which will be visualized along the input sequence.
![]()
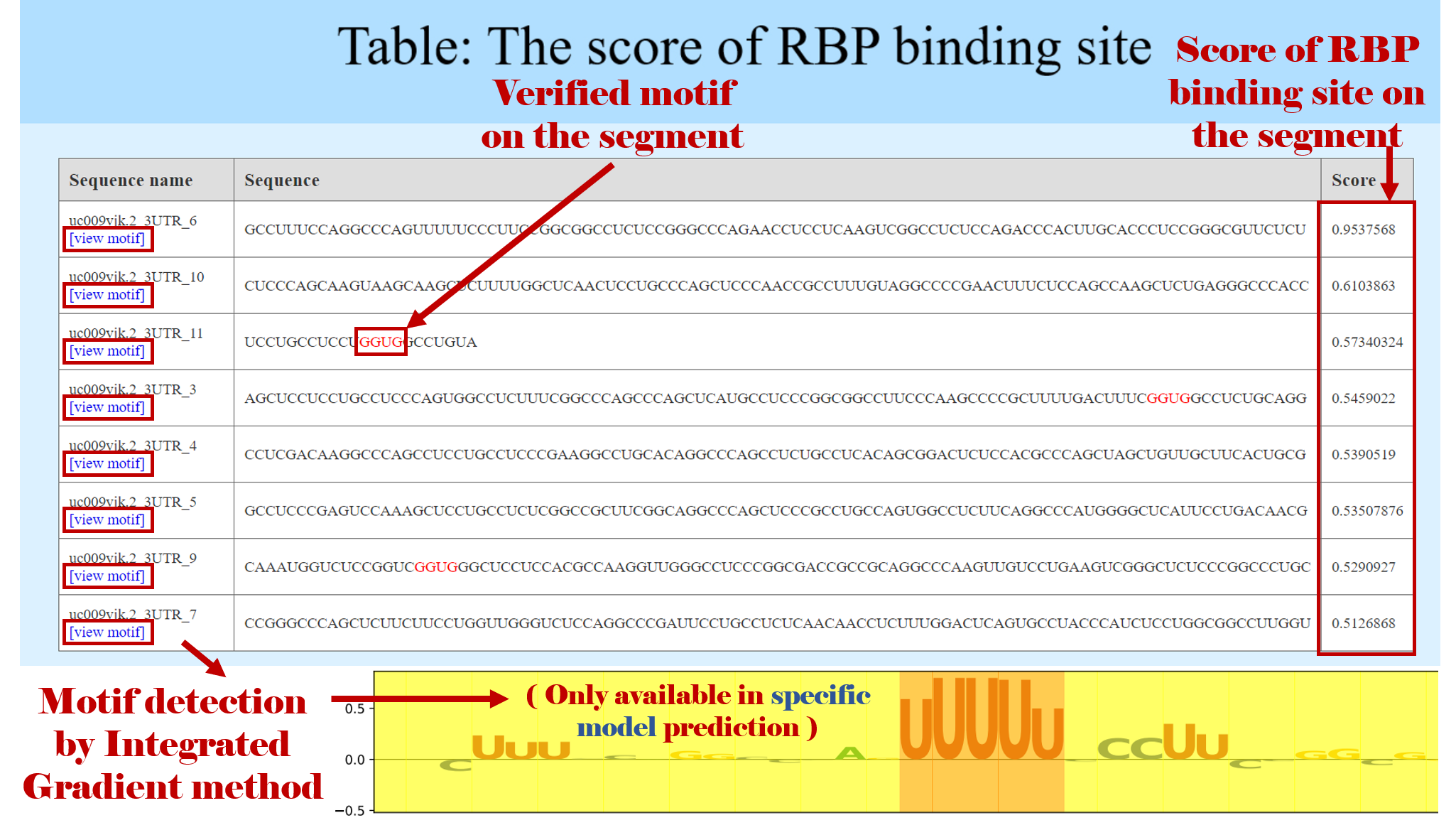
In order to improve the efficiency of the calculation, RBPsuite divides the input sequence into segments of length 101 without overlap and displays the score of each segment with the RBP of interest in the table. In addition, RBPsuite has numbered the sequence segment according to the orders in the input sequence like _1,_2,_3... in the first column of the table,
_1 means the first 101nt segment, _2 means the second 101nt segment and so on, along the input sequence. These segments are arranged in descending order of score, and segments with a score less than 0.5 are filtered out. When the RBP has a verified motif file, for the segments with a score greater than 0.5, RBPsuite marks the possible motifs in RED according to the position on the segment.
(using the MEME-fimo tool: http://meme-suite.org) What's more, RBPsuite provides a sort function. You can click the name of each column to sort the results in ascending and descending order. (the "sequence" column is not supported).
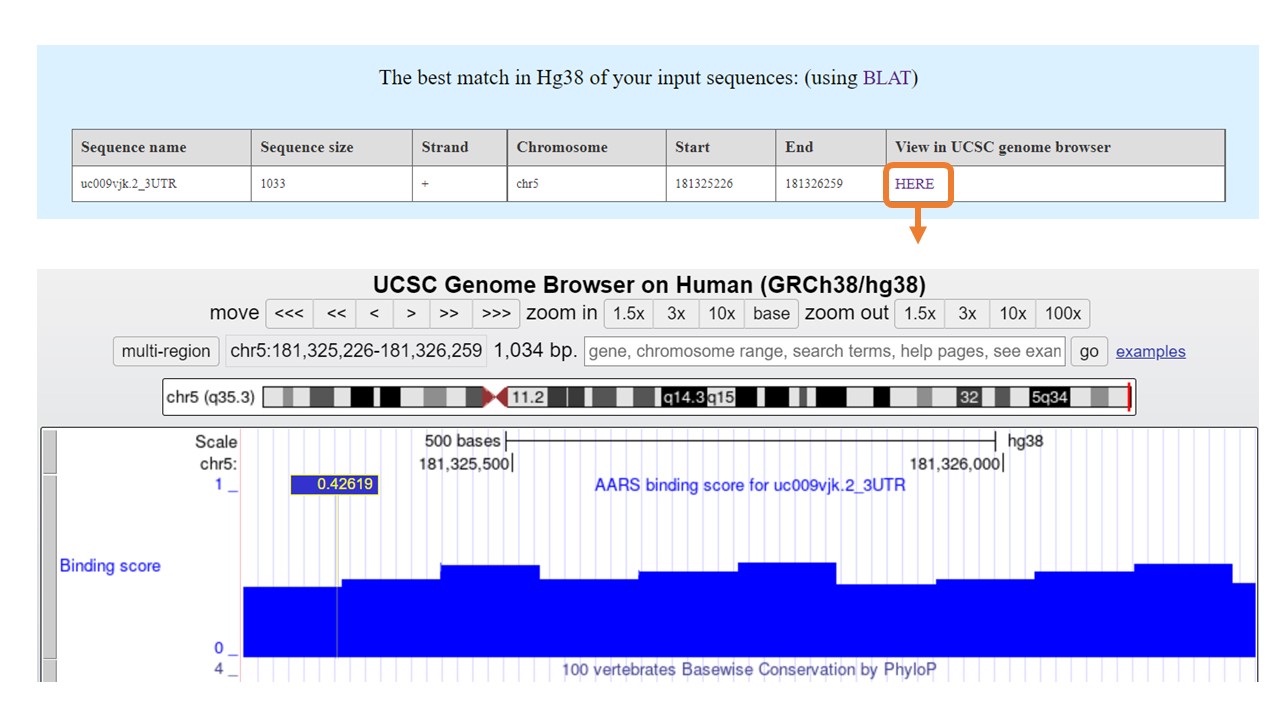
RBPsuite provides the best match of the input sequence in genomes for 4 species (Human: GRCh38/hg38; Mouse: GRCmm39/mm39; Fly: BDGP Release 6 + ISO1 MT/dm6; Yeast: SacCer_Apr2011/sacCer3) by BLAT. The detailed information includes sequence length, chromosome, strand, start index, and end index. Besides, RBPsuite visualizes the input sequence with the binding score track(prediction score on the sequence) by the UCSC genome browser.
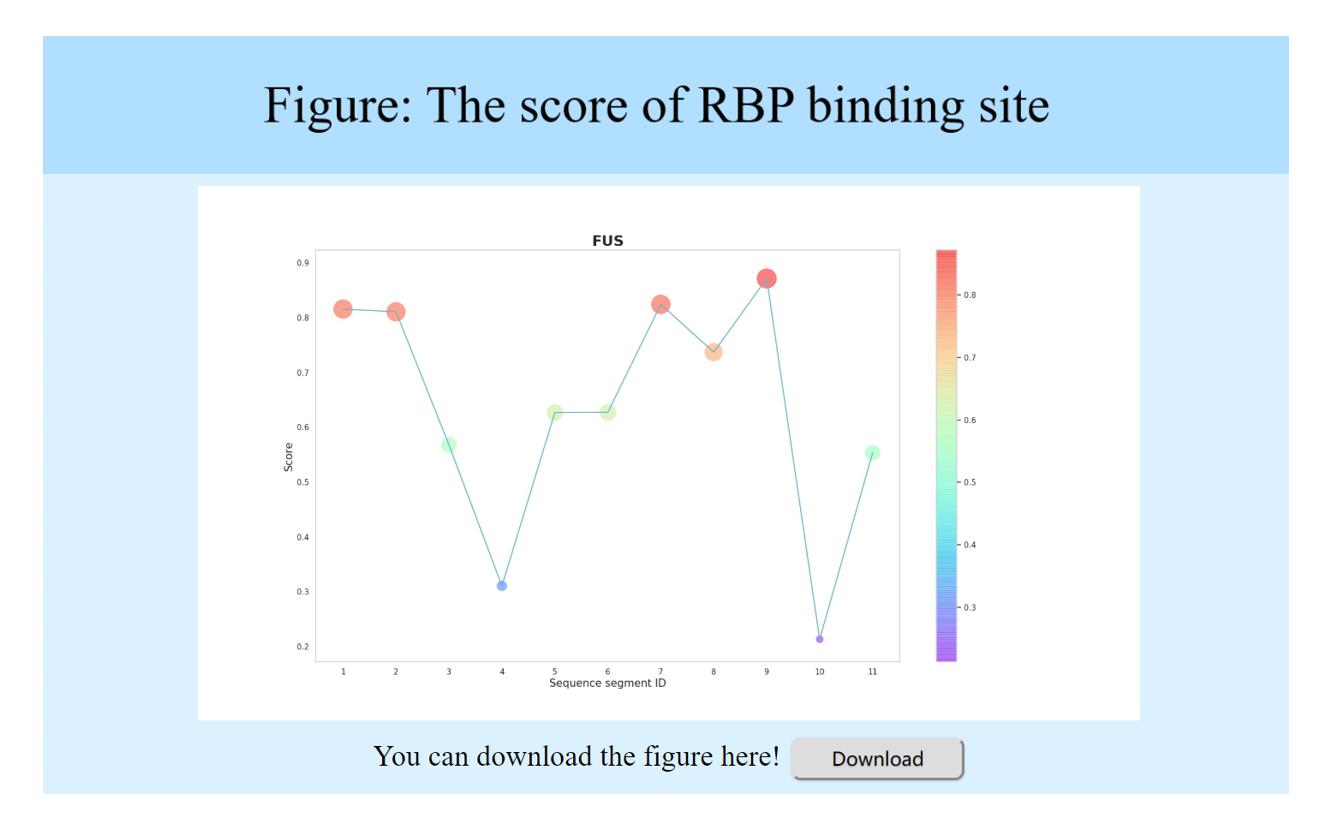
RBPsuite also provides visualization for the binding scores of the segments along the input sequence, it displays the scores in a direct way.
2. All models
Different from the specific model, the 'all models' option has a directory interface that lists all the RBPs, which predict binding scores between your input RNA and the model trained for this RBP. The results that have been finished are displayed in blue, and those displayed in gray means not finished yet. For more details about the prediction results of individual RBPs, the users can click the RBP of interest to see the predicted RBP binding sites of this RBP for the input sequence. The result page of each RBP is the same as the specific model.
Q&A
Question: The result page URL stays grey and accessing it results in a 403 Forbidden error.
Answer: Please check if your input file is in FASTA format.
ACGTUACGTU #seq1
acgtuacgtuac #seq2
#A fasta format sequence must start with a line that begins with a greater-than-character (">").
#The program will automatically recognize the newline character (\n|\r|\r\n) and treat the sequence following it as another sequence.