|
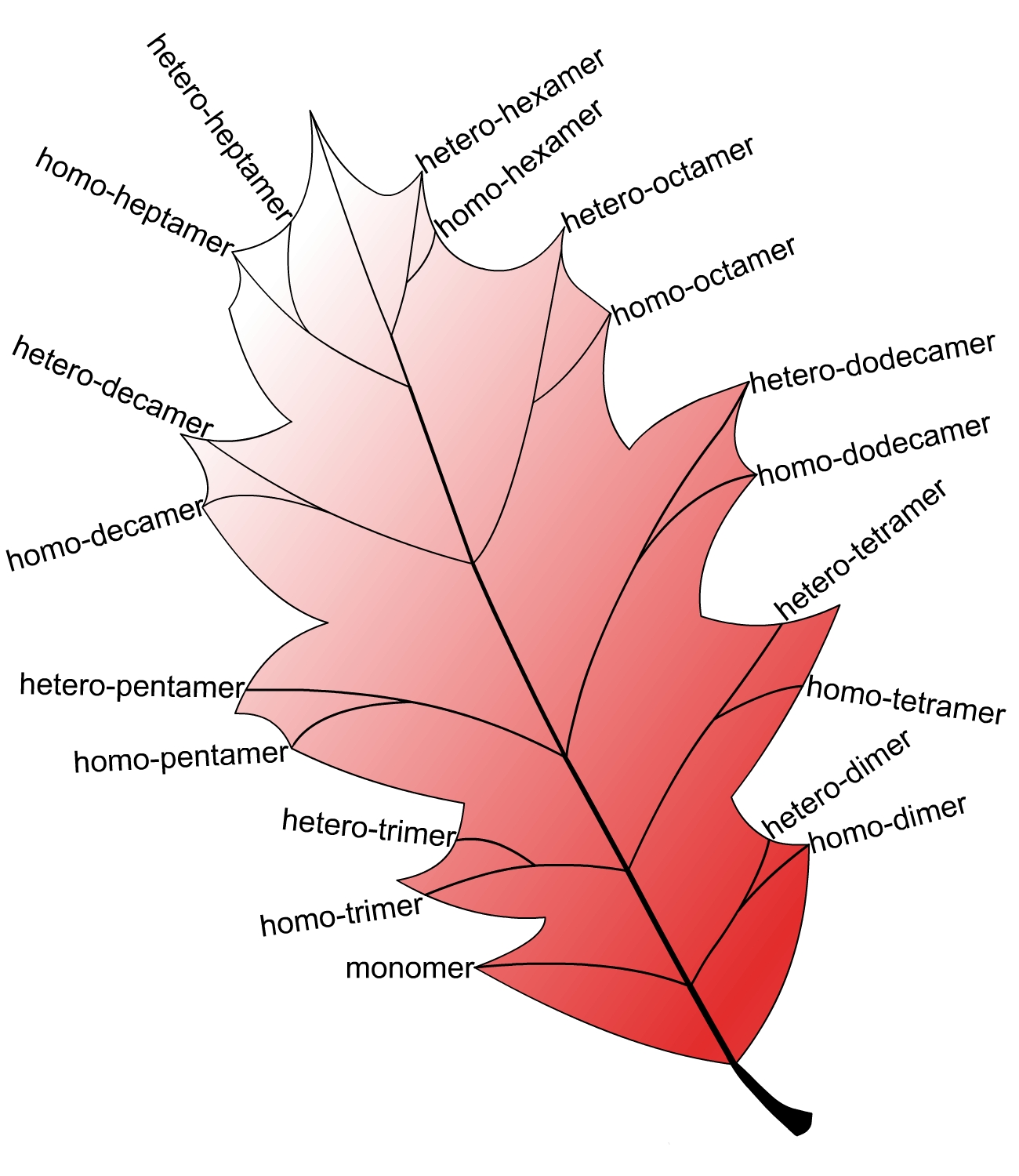
The protein universe contains both single-chain proteins and multiple-chain proteins. According to the number of the constituent chains, proteins can be classified into many different quaternary structural attributes, such as monomer, dimer, trimer, and so forth (see the schematic drawing below). They are the structural bases of various marvelous biological functions such as cooperative effects, allosteric mechanism, and ion-channel gating.
|
|
The web server QuatIdent (Quaternary Identifier) was developed by fusing the functional domain and sequential evolution information. QuatIdent is a 2-layer predictor. The 1st layer is for identifying a query protein as belonging to which one of the following ten main quaternary structural attributes: (1) monomers, (2) dimmer, (3) trimer, (4) tetramer, (5) pentamer, (6) hexamer, (7) heptamer, (8) octamer, (9) decamer, and (10) dodecamer. If the result thus obtained turns out to be anything but monomer, the process will be automatically continued to further identify it belonging to a homo-oligomer or hetero-oligomer. The overall expected success rate by QuatIdent for the 1st layer identification was about 71% and that for the 2nd layer ranged from 84% to 96%. For a query protein sequence of 200 amino acid residues, it will take around 25 seconds to get the desired 2-level results.
|